Think of the internet as a huge library that contains billions of volumes of information, and if there is no way to track all this information, you will never be able to locate what you need. They have automated machines that help catalog and track this information. This is the same with regard to SEO (search engine optimization) and crawlers. In this space, a crawler is like an automated librarian that reviews the web, reading through different pages, and reports back to the search engine and helping the search engine decide what is more pertinent to show a user on a particular search query.
A noted crawler is one that a search engine trusts, and it could be bots from a search engine like Google or Bing that know and obey the rules for indexing your site. The most important point to recognize is that the listed crawlers are what matter the most when it comes to seeing your website in the search results. If you accidentally block a listed crawler, it can also cause you to be removed from search results.
This article will cover the basics of listed crawlers, how they function, how they are important for SEO, and how you should optimize your website. We will take a look at the listed crawlers, what the difference is from an unlisted crawler, and best practices to follow, common problems that might arise, and even look towards the future and discuss AI trends. After reading this article, you will know more about the listed crawlers and will be provided with a plan to make your site crawler-friendly.
What is a Listed Crawler?
A listed crawler is a bot that has been authorized by search engines to find and aggregate on web pages. It is “listed” because it is recognized and adheres to common internet protocol – it’s legit, just like trust, and it cannot hurt you – it’s a known entity. Think of it like a guest at a party, who was invited with a clear expectation, and should behave.
Crawlers, bots, and spiders are often used interchangeably, but there is a slight difference. They all refer to automated programs that browse the web. “Crawler” or “spider” refers more to how they “crawl” from link to link like a spider moving on the lines of a web, while “bot” is a broader term that could apply to any form of automated script. Listed crawlers are the good ones from the known entities.
Examples of listed crawlers include: Googlebot (which is also the ubiquitous search engine behavior of Google.com), Bingbot (for Microsoft Bing), YandexBot (from Yandex in Russia), Baiduspider (from Baidu in China), DuckDuckBot (from DuckDuckGo, which focuses on privacy), and GPTBot (from OpenAI). 2025 has brought growth in AI bots, with OpenAI’s GPTBot claiming a 305% increase in traffic from 2024 to 2025.
There are other AIs that are becoming part of our crawling environment, too. Each of these bots scans billions of pages on a daily basis in order to display relevant results in the elements of every search results page.
Why Are Listed Crawlers Important?
Listed crawlers are an important piece of how search engines index and rank sites. They crawl your pages, fetch, evaluate content, and put them in the search index. Basically, if your site is not crawled by a crawler, it won’t be found in the results.
Listed crawlers have a significant influence on your site’s visibility in search engine results pages (SERPs). In particular, if your site is searched or optimized for crawlers, you will have better rankings and inherently more traffic. Statistically, 53 percent of all traffic to websites comes from search engines.
Moreover, Google is projected to have a market share of 89.74% in 2025, and if Googlebot crawls your site, you will have a better chance of being able to be on the first page when a searcher uses Google.
There are many advantages for businesses, bloggers, sponsored content, and ecommerce sites. The advantages are better visibility, which translates to more visitors, sales, and engagement. For ecommerce websites, you can see that some sites have a greater traffic level of approximately 20-30% from proper crawling alone.
Blog readers increase the number of visitors to your blog. Platform sites build trust and brand equity for consumers. In a time when 96.55% of web pages on the Internet receive no Google search engine traffic at all, if you want to be a customer champion, listed crawlers are the way to go to stand out.
Benefits
- Increased organic traffic and conversions.
- Better user experience through accurate indexing.
- Competitive edge in crowded markets.
Listed Crawler vs. Unlisted Crawler
Listed crawlers are authorized and known (like brown trucks from FedEx), identifiable user agents ( think ‘Googlebot’), and abide by site rules, while unlisted crawlers are unknown or are suspicious crawlers that come either from scrapers or malicious bots that can steal your information or overload your server.
There are two key differences between the two types of crawlers; the listed ones can help with SEO since they will index your content ethically, while the unlisted ones might either. Block websites, or, worse, ignore all robots.txt or sitemap files or even malicious requests that may lead to a security risk. As Search Engines like Google only trust listed crawlers, it should be noted that listed crawlers are: verifiable, abide by the rules, and predictable to some extent, allowing search engines to provide very relevant results.
In the case of “Accidental block-listed crawlers,” you have significant negative outcomes since dropping your rankings could be instantaneous. For example, if I block Googlebot in my robots.txt, my site would never get indexed or listed in the SERPs, so I wouldn’t be visible anywhere.
It’s important to realize we are using 2025 search statistics of 18% growth in AI and crawler traffic, and blocking listed crawlers could mean missing out on taking advantage of future trending SEO.

Features of Listed Crawlers
- Identifiable and rule-following.
- Beneficial for indexing.
- Trusted by search engines.
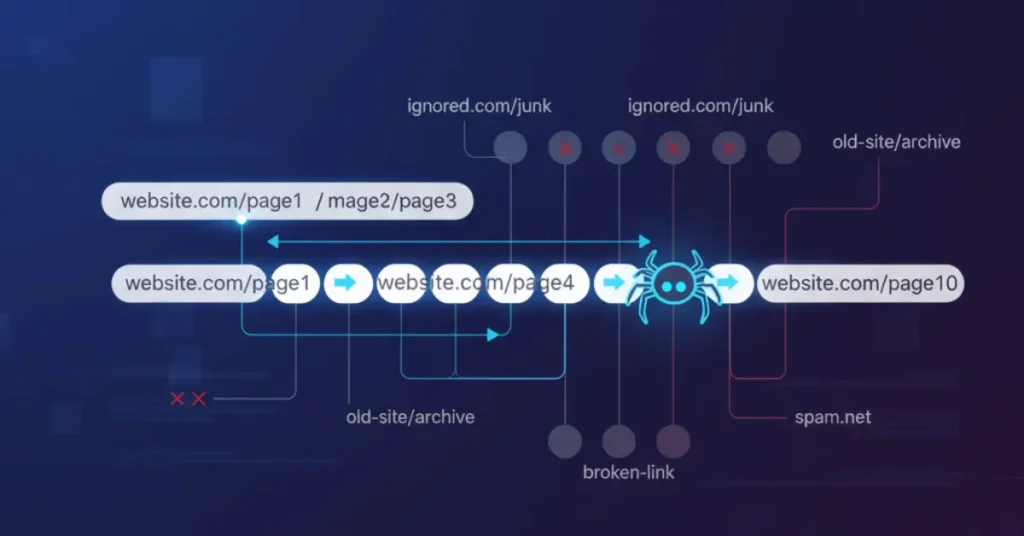
How Do Listed Crawlers Work?
Listed crawlers use this process: crawl, analysis, index, then rank.
There are only four steps.
First, they’re going to crawl starting at a known site and following links to find new pages. When a crawler hits a page, it will analyze the page, looking at the text, images, and where information appears on the page. After crawling and analyzing a page, they will index it, collecting data and entering it into a huge database. Lastly, they will use algorithms to rank the page for search result retrieval, based on its relevance and authority.
Robots.txt files tell crawlers what pages they can and can not crawl. For example: “Disallow: /private/”. Sitemaps list all of the pages that are important for crawlers, which makes it easier for crawlers to discover and index pages. Crawlers will follow rules, like crawl delays (to avoid crashing servers), and disallow directives.
As an example, if BingBot crawls your homepage for a listed crawling search engine, it might follow links on your homepage to internal pages and posts. If those pages are crawled and indexed, it would happen quickly, compared to the delay in search results for a new post.
How It Works in Detail
- Crawl: Discover via links.
- Analyze: Read and understand content.
- Index: Add to search database.
- Rank: Position in results.
How to Check If a Listed Crawler is Visiting Your Site
Start with server logs; they record every visit, including user agents. Look for entries like “Mozilla/5.0 (compatible; Googlebot/2.1; + http://www.google.com/bot.html)” to spot real ones.
Tools make it easier. Google Search Console shows crawl stats, errors, and bot visits. Bing Webmaster Tools does the same for Bingbot. Other options include Ahrefs or SEMrush for broader tracking.
To identify fake vs. real, verify user agents against official lists. Real Googlebot IPs can be checked via reverse DNS. Fake ones might mimic but come from odd IPs. In 2025, with crawler traffic rising, regular checks will prevent issues.
Solutions for Tracking
- Use logs and tools daily.
- Verify with official docs.
- Set alerts for unusual activity.
Best Practices for Optimizing Your Website for Listed Crawlers
By making your pages crawlable, by having your links work, and your pages load quickly. And, of course, do not block critical areas in robots.txt. Generate and submit an XML sitemap using Google Search Console, which lists all your URLs so that they can be found easily. Gear it for speed. Websites that load under 3 seconds get crawled much quicker. This is a big factor, especially as 63.31 % of all web traffic in 2025 is on mobile devices.
Use structured data, such as what you can find at schema.org, to help crawlers interpret your content easily for chances at rich snippets. Also, duplicate content and broken links may create wasted crawl and infinite crawl with crawlers revisiting a previously seen URL. Fixing them prevents wasting crawls.
Benefits of Optimization
- Faster indexing and higher rankings.
- Improved user satisfaction.
- Long-term SEO gains.
Common Mistakes That Block Listed Crawlers
A wrong robots.txt is basically like accidentally blocking all bots with your “Disallow: /”. That’ll block everything, even the listed crawlers.
A surplus of “noindex” tags is going to hide your pages from being indexed. Blocking resources, like CSS or JS, makes it impossible for crawlers to render a page correctly, as most bots today use JavaScript.
Bad internal linking renders pages orphaned; there’s a reason I find stats say that broken links result in 15% of all crawl errors. Redirect chains are bad and bottleneck crawls.
Solutions to Avoid Mistakes
- Test robots.txt regularly.
- Use noindex sparingly.
- Audit links and resources.
Future of Listed Crawlers in SEO
They have an improved context and predicting user needs.
Voice search, mobile-first indexing, and Core Web Vitals are going to run the game in 2025. AI Overviews will expand into all queries, with a resulting 30% reduction in clicks, while optimized sites will have more visibility. By 2027, generative AI could be used by 70% of Gen Z.
Listed crawlers will evolve with AI and focus on quality instead of quantity. Plus, remember last year’s crawler chats – expect these historical features to inevitably be integrated with current LLMs to enable real-time answers.
Predictions
- Smarter, AI-powered bots.
- Shift to answer engines.
- Emphasis on user intent.
Key Takeaways
- Listed crawlers are official search engine bots that index web content
- The global SEO services market is projected to reach $146.96 billion in 2025
- GPTBot jumped from #9 in May 2024 to #3 in May 2025, showing the rise of AI crawlers
- General invalid traffic rose by 86% in the second half of 2024 due to AI crawlers
- Properly managing crawler access can significantly improve your website’s search visibility
Conclusion
Crawlers are necessary for SEO, provided they are listed crawlers like Googlebot or Bingbot. Listed crawlers are important because they have to index your site and rank it for your keywords. They increase visibility and traffic, growing businesses, bloggers, and ecommerce sites. You should do a few things to ensure you are friendly to crawlers: check your robots.txt file, submit an XML sitemap, make sure your site loads quickly, and implement structured data. Make sure you don’t make errors like blocking your resources or overusing noindex tags.
Now, with AI that will change the future of crawling, it is important to audit your site, so you can be ready for the trends anticipated in 2025. In this case, taking action is the keyword. Use Google Search Console and other tools to make sure listed crawlers can access your website and improve your SEO efforts.
FAQs
What is a listed crawler in SEO?
A listed crawler is a trusted and authorized robot from a legitimate search engine, such as Googlebot or Bingbot, that will crawl and scrape websites to collect data and index them. A listed crawler essentially supports your site and makes it easier for it to appear in search results by obeying the rules of the web and indexing it the correct way!
How is a listed crawler different from an unlisted crawler?
Listed crawlers are a trusted and verifiable source from known search engines that will be beneficial to the SEO process by correctly indexing your site’s content. Unlisted crawlers are unknown and potentially malicious sources that tend not to care about rules maliciously, and could result in potential security risks or server overload situations.
Why are listed crawlers important for my website?
They are really important for crawling and ranking your site on search engines. Good crawling increases the visibility of your website in search results, and you get more traffic. Search engines send about 53% of all traffic to websites, so listed crawlers are pretty important.
How can I check if a listed crawler is visiting my site?
You can track crawlers through your server logs by tracking user agents like “Googlebot.” You can also see crawl activity in Google Search Console or Bing Webmaster Tools. and these have features to help you identify if the crawler is real versus not.
Can blocking a listed crawler harm my SEO?
Blocking indexable crawlers, such as accidentally disallowing Googlebot via robots.txt, will prevent your site from being indexed, making your site invisible to searchers and dramatically limiting your traffic and ranking in the results.
What are the best ways to optimize my site for listed crawlers?
Make sure your site is crawlable with valuable links, has an XML submitted to Search Console, loads in less than 3 seconds, is mobile responsive, is structured data optimized, none of your pages have duplicate content, and that you don’t have any broken links on your site.
What common mistakes should I avoid with the listed crawlers?
Your robots.txt file should not be misconfigured to exclude all bots; you don’t want to overuse noindex tags on many pages, blocking CSS or JavaScript resources, and your internal linking structure should be in good shape so crawlers have a path through your site.